🚀 Setup Spark Cluster
Hướng dẫn cài đặt và cấu hình Spark Standalone Cluster với 1 Master + 2 Worker node.
🚀 Setup Spark Standalone Cluster (2 nodes)
Spark có thể chạy trên nhiều cluster manager khác nhau như Standalone, YARN, Mesos, Kubernetes.
Trong bài viết này, mình sẽ dựng Spark Standalone Cluster 2 node ( với 1 node vừa đóng vai trò Master, vừa đóng vai trò Worker, và 1 node chỉ đóng vai trò Worker). Đây là setup cơ bản để học tập, thử nghiệm nhé.
📌 Môi trường
- Master + Worker:
100.83.165.19, ở đây máy này đóng cả 2 vai trò Master và Worker nhé. (Spark ở/home/hien/spark, RAM 16GB, 8 cores) - Worker:
100.112.156.29(Spark ở/home/noname/dev/spark, RAM 8GB, 4 cores) - Cả 2 máy đều có Java (
openjdk-11-jdkhoặcopenjdk-21-jdk) và PySpark. - Đã setup SSH key không mật khẩu từ Master → Worker.
1. Cài Spark Binary
Trên mỗi máy tải và giải nén Spark (hoặc copy từ master):
1
2
3
wget -c https://archive.apache.org/dist/spark/spark-3.5.0/spark-3.5.0-bin-hadoop3.tgz
tar -xvzf spark-3.5.0-bin-hadoop3.tgz
mv spark-3.5.0-bin-hadoop3 ~/spark
2. Thiết lập biến môi trường
Thêm vào ~/.bashrc:
Master (100.83.165.19)
1
2
3
4
export SPARK_HOME=/home/hien/spark
export PATH=$SPARK_HOME/bin:$PATH
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
Worker (100.112.156.29)
1
2
3
4
export SPARK_HOME=/home/noname/dev/spark
export PATH=$SPARK_HOME/bin:$PATH
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
3. Cấu hình Spark Master
File: $SPARK_HOME/conf/spark-env.sh (Master)
1
2
3
export SPARK_MASTER_HOST=100.83.165.19
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
File: $SPARK_HOME/conf/spark-env.sh (Worker)
1
2
3
export SPARK_LOCAL_IP=100.112.156.29
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
4. Start / Stop Cluster Scripts
start-cluster.sh
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#!/bin/bash
MASTER=100.83.165.19
SPARK_HOME_MASTER=/home/hien/spark
SPARK_HOME_WORKER=/home/noname/dev/spark
echo ">>> Starting Spark Master ..."
$SPARK_HOME_MASTER/sbin/start-master.sh
echo ">>> Starting Worker on Master ..."
$SPARK_HOME_MASTER/sbin/start-worker.sh spark://$MASTER:7077
echo ">>> Starting Worker on Worker node ..."
ssh noname@100.112.156.29 "$SPARK_HOME_WORKER/sbin/start-worker.sh spark://$MASTER:7077"
echo ">>> Cluster started. Check UI at http://$MASTER:8080"
stop-cluster.sh
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#!/bin/bash
MASTER=100.83.165.19
SPARK_HOME_MASTER=/home/hien/spark
SPARK_HOME_WORKER=/home/noname/dev/spark
echo ">>> Stopping Worker on Worker node ..."
ssh noname@100.112.156.29 "$SPARK_HOME_WORKER/sbin/stop-worker.sh"
echo ">>> Stopping Worker on Master ..."
$SPARK_HOME_MASTER/sbin/stop-worker.sh
echo ">>> Stopping Spark Master ..."
$SPARK_HOME_MASTER/sbin/stop-master.sh
echo ">>> Cluster stopped."
Cấp quyền:
1
2
chmod +x start-cluster.sh stop-cluster.sh
Note:
Nếu có nhiều worker node :
- Nếu bạn muốn chạy
$SPARK_HOME/sbin/start-all.sh(nó sẽ tự start master và các workers theo danh sách trongconf/workers). - Khi bạn có nhiều worker cố định và muốn start/stop đồng loạt bằng 1 lệnh (
start-all.sh,stop-all.sh), thay vì viết script riêng thì cấu hình fileconf/workers
Ví dụ
conf/workers:1 2
100.83.165.19 100.112.156.29
Rồi chỉ cần chạy:
1 2
$SPARK_HOME/sbin/start-all.sh $SPARK_HOME/sbin/stop-all.sh
- Nếu bạn muốn chạy
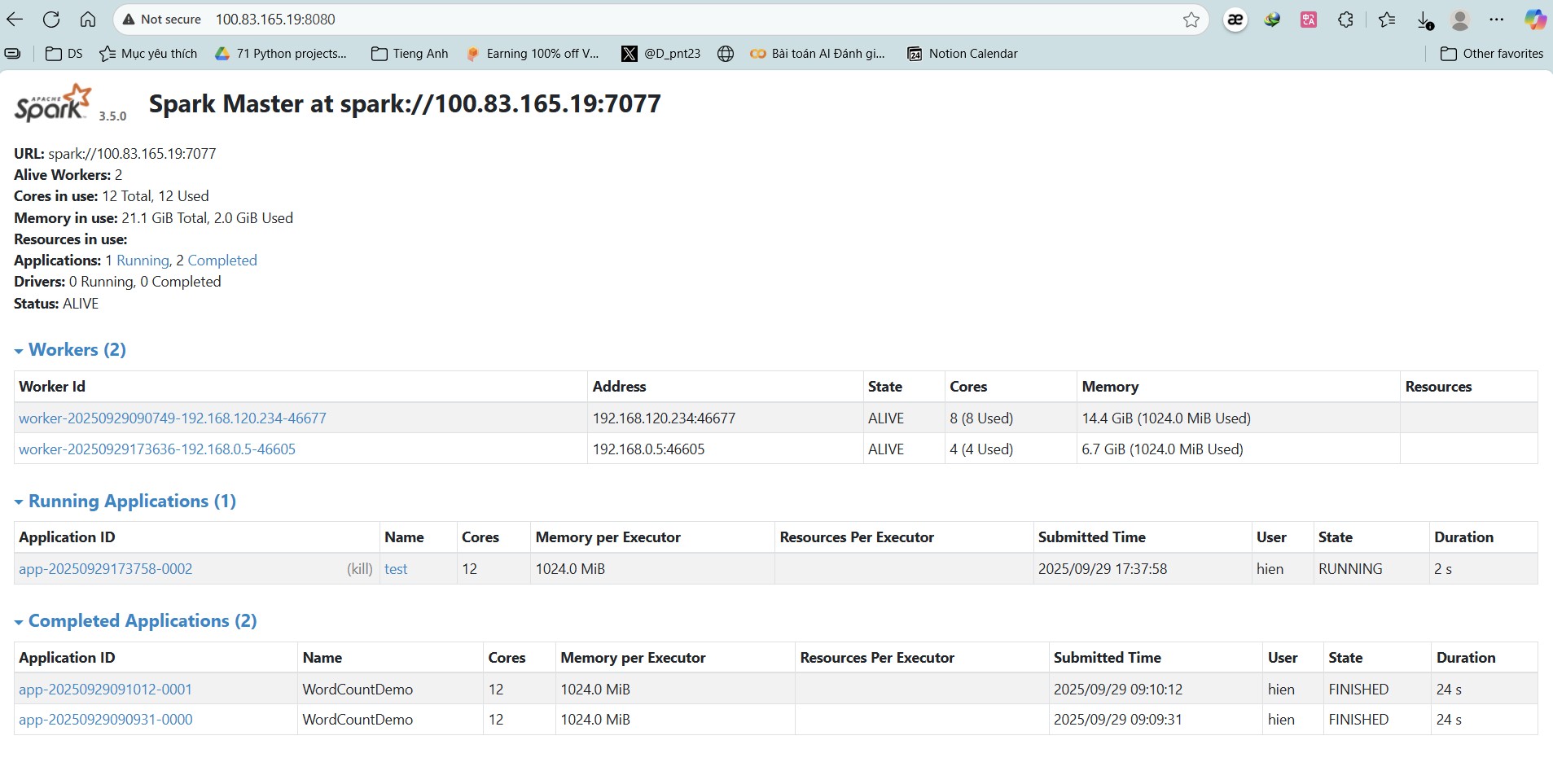
5. Kiểm tra Web UI
- Master UI: http://100.83.165.19:8080
- Application UI (khi job chạy):
http://<driver-host>:4040
6. Chạy job demo
wordcount.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("WordCountDemo").getOrCreate()
data = [
"hello spark cluster",
"spark makes big data easy",
"hello world",
"big data big challenge"
]
rdd = spark.sparkContext.parallelize(data)
word_counts = (rdd.flatMap(lambda line: line.split(" "))
.map(lambda word: (word, 1))
.reduceByKey(lambda a, b: a + b))
for word, count in word_counts.collect():
print(f"{word}: {count}")
spark.stop()
Chạy trên Master:
1
2
$SPARK_HOME/bin/spark-submit --master spark://100.83.165.19:7077 wordcount.py
✅ Kết quả
- Cluster 2 node, tổng cộng 12 cores / 21.1 GiB RAM
- Spark Master:
spark://100.83.165.19:7077 - Worker1:
192.168.1.61(8 cores, 14.4 GiB) - Worker2:
192.168.0.5(4 cores, 6.7 GiB) - Job demo chạy thành công, hiển thị trong Spark WebUI.
Như vậy, bạn đã có một cluster Spark nhỏ gọn, sẵn sàng chạy các job phân tán với PySpark rồi.